AntsDB Architecture
AntsDB takes a different approach than most mainstream relational databases. The market dominators, aka the old school RDBMS, follows very similar architecture despite small differences in features and performance. If you open the hood, you will see b-tree, redo/undo log, thread pool, transaction manager, metadata manager, lock manager etc. Very much like the gasoline vehicles, it is always the same components but in different shapes, sizes and performance characteristics depending on what brand/model of the car you are looking at.
The trending NoSQL/NewSQL databases are very different than the old school RDBMS. But among them, they also share very similar architecture. Pretty much all of them are built with write ahead log, log structured merge tree, cluster management, replication etc.
AntsDB doesn’t really fall into any of the two categories above. Our mission is to create a hybrid database engine that is both OLTP and OLAP. AntsDB is OLTP because it provides features that is critical in building a front-end application such as ACID, sub-millisecond latency, rich transaction management, SQL compliance and powerful lock management. It is also a OLAP because the storage AntsDB sits on is a data warehouse. AntsDB also acts like a middleware. It is a stateless transaction processor with a big local cache.
Thus it leads to an architecture shown in the diagram below.
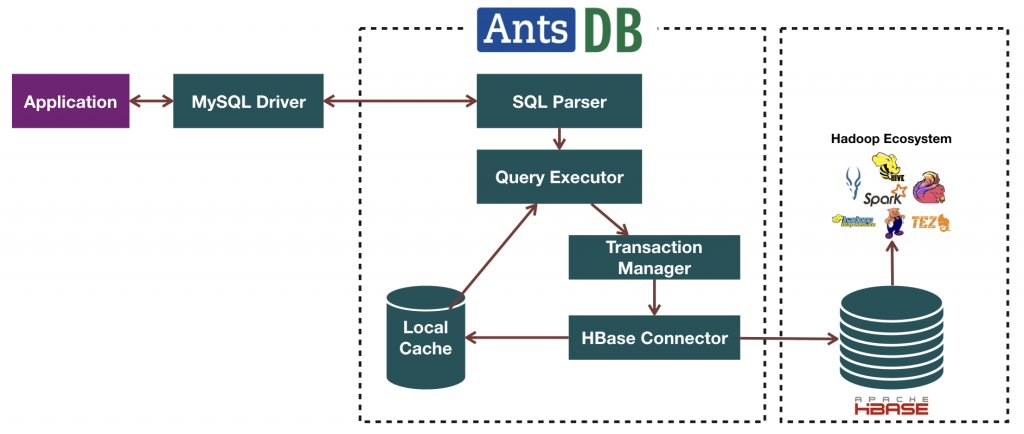
AntsDB Architecture
AntsDB is built with 3 layers. The outmost layer is the MySQL compatibility layer. There are two components: network protocol and SQL parser.
The network protocol is a full MySQL 5.5 protocol implementation. It is written using asynchronous I/O with the help from popular Netty project. Asynchronous I/O grants AntsDB the advantage to serve large amount of current users with a very small thread pool. Traditional DBMS uses synchronous I/O. It has to create exclusive thread for each user. Thread is an expensive system resource. It doesn’t scale well.
SQL is a high level language. We need to break the complex logic into smaller and simpler parts such as functions, operators, joins etc. The parser is responsible of this task. At the end of parsing, it generates a number of “instructions” which runs in the virtual database machine. Result of the parser is cached in a small pool in memory. If the frond-end application sends duplicate SQL statements, the expensive parsing phase can be simply skipped. Most applications today do that with prepared statements.
We wanted AntsDB to be not only compatible with MySQL but also other types of database in the future. Thus it comes with the idea of database virtualization. VDM – virtual database machine – is what makes it come true inside AntsDB. VDM is a runtime environment with hundreds of small logic unit such as functions, joins, operators etc. Beside the small building blocks, there are 3 important components in VDM serving them.
Transaction Manager makes sure that multiple data manipulations act as a single unit of work. It uses a 64 bit number internally to track every single transaction in the system. Once the transaction is completed. It assigns another 64 bit number to the updates as the version of the update. The version is subsequently used in transaction isolation and MVCC (multi-version concurrency control).
Metadata Manager manages the life cycle of user objects, aka as tables, columns, constraints etc. It maps human readable names to memory locations, file locations and unique identifiers that works efficiently at the hardware level.
SQL query is a high level abstract language. Typically database software needs to break the query into many joins, table lookups and table scans. Unfortunately, there are many different ways to do it. Some could be more efficient than the others. That’s where the query planner kicks in. It evaluates all possibilities intelligently and decides the least expensive way of execution.
At the very bottom of the layers sit the AntsDB KV – key value store. We have the top layer responsible of MySQL compatibility, mid layer manages the complexity of SQL language. The AntsDB KV’s job is to deal with performance and concurrency.
At the heart of AntsDB KV, it is the LSMT store. LSMT – log structured merge tree – is a way to organize database files. It’s been known to be much superior in terms of I/O efficiency than page based storage used in most mainstream databases. The data in LSMT is more compact. It takes advantage of high throughput sequential I/O while page store is depending on slow random I/O. Inside LSMT, AntsDB uses skip list data structure other than B tree used in most mainstream databases. Skip list utilizes CPU level atomic operations to mange data contention and performs extremely well in high current situations while B tree uses expensive mutex.
As a database, AntsDB has to be prepared for the worst. Power can go down. Hardware can malfunction. We use a technique – write ahead log, aka redo log – exists in almost all databases today to recover from failures. As soon as the transaction commits, updates is guaranteed to be written to the WAL. After a system crash, AntsDB uses data from WAL to rebuild LSMT next time it starts.
The last component in KV store is the replicator. Its responsibility is to send data to HBase as soon as the updates is committed in a sub-second manner.
Above summarizes the AntsDB architecture from a very high level. We will cover some of the components in more detail later.
Leave a Reply