Blog
Again, AntsDB tops at TPC-C benchmark
AntsDB 18.05.27 is released with new open source license
AntsDB 18.05.27 is a maintenance release with a number of performance and stability improvements. Not only is this release making everything run faster and better, it also comes with an important license change.
AntsDB 18.05.02 is released with new network transportation layer
AntsDB 18.05.02 comes with a brand new implementation of MySQL protocol. It is 200% faster than previous version of AntsDB in our benchmark. Below is the list of changes in this release
- Buffering with direct memory instead of on heap Java object. It is not only faster but also saving significant system resource taken by garbage collection
- Removed unnecessary thread switch in asynchronous network I/O handling which leads to better response time and savings on system resource
- Optimization for very large result set. New mechanism will pause the network communication if the client can’t consume the result faster enough
Now go to the download page and try it.
YCSB benchmark, AntsDB beats mainstream relational databases by more than 100%
Introduction
YCSB stands for Yahoo! Cloud Serving Benchmark. It is the de facto database benchmark today. It supports a wide range of database types with a pluggable architecture that can be easily expanded to measure new database technologies.
Benchmark Methods
The benchmark used 30 million records data volume. Each record is 1 KiB in size. We used 4 benchmark workloads provided by YCSB.
- Loading benchmark – loading 30 m records into an empty database. It is used to measure the data import performance.
- Read only benchmark – it is used to measure analytic performance of a database
- Read heavy (90% read 10% write) – it is used to measure the performance of user interactive applications.
- Write heavy (50% read 50% write) – it is used to measure the performance of batch processing applications.
Benchmark Setup
The benchmark was performed on Amazon AWS EC2 i3.4xlarge instance. Below is the summary of the system configuration.
| CPU | Intel(R) Xeon(R) CPU E5-2686 v4 @ 2.30GHz, 8 cores, 16 threads |
| Memory | 122 GiB |
| Storage | 1.7T * 2 NVMe SSD |
| Operating System | CentOS 7.4.1708 |
| Comparing Database | MySQL 5.5.56, PostgreSQL 9.2.23, Database O 12.2.0.1.0, AntsDB 18.05.02 |
| Java | 1.8.0_161-b14 |
Database Configuration
| AntsDB | humpback.space.file.size=256 humpback.tablet.file.size=1073741824 |
| MySQL | innodb_file_per_table=true innodb_file_format=Barracuda innodb_buffer_pool_size=50G innodb_flush_log_at_trx_commit=0 max_connections=200 |
| PostgreSQL | shared_buffers = 30GB bgwriter_delay = 10ms synchronous_commit = off effective_cache_size = 60GB |
| Database O | MEMORY_TARGET=50g |
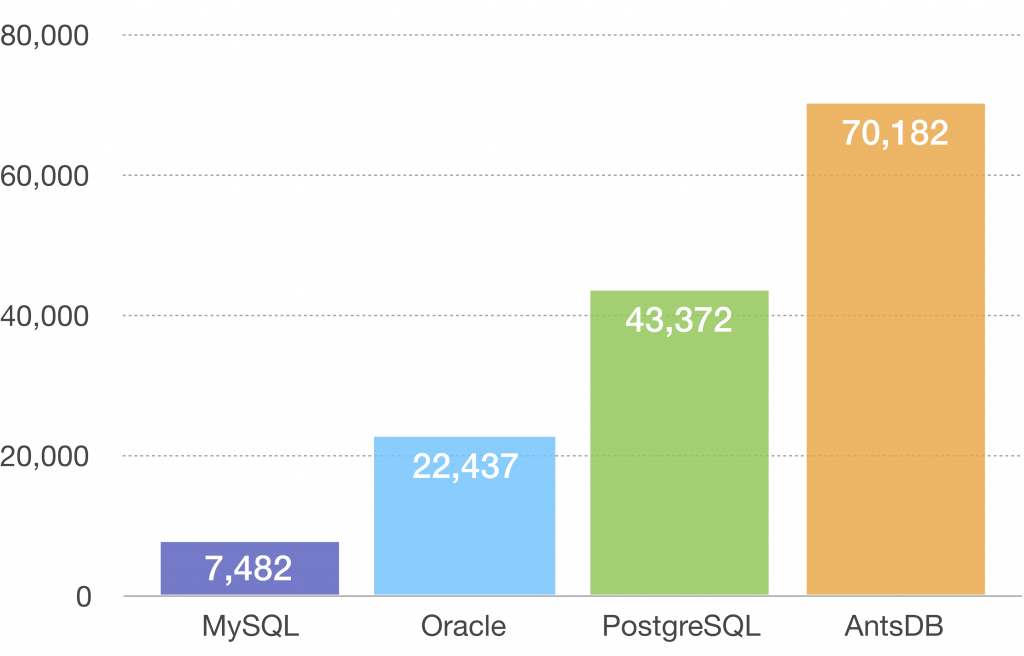
Loading Test
The data was imported into database using 16 threads. Unit of measurement is records/second.
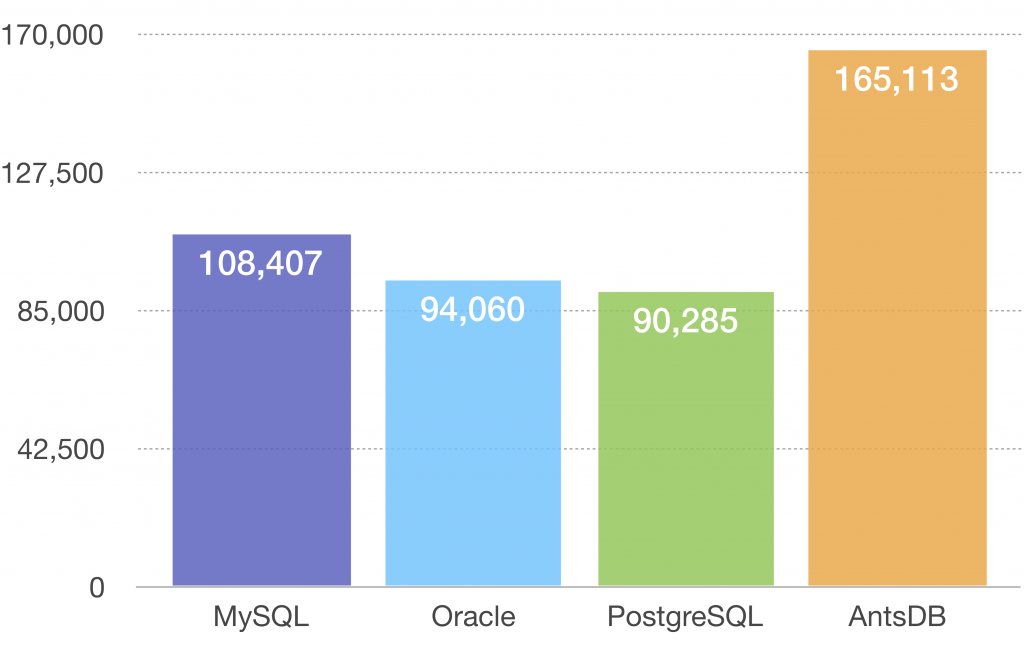
Read Only Test
The test was conducted using different number of threads. All tested databases achieved the highest throughput with 24 threads as show in the diagram below. Unit of measurement is transactions/second.
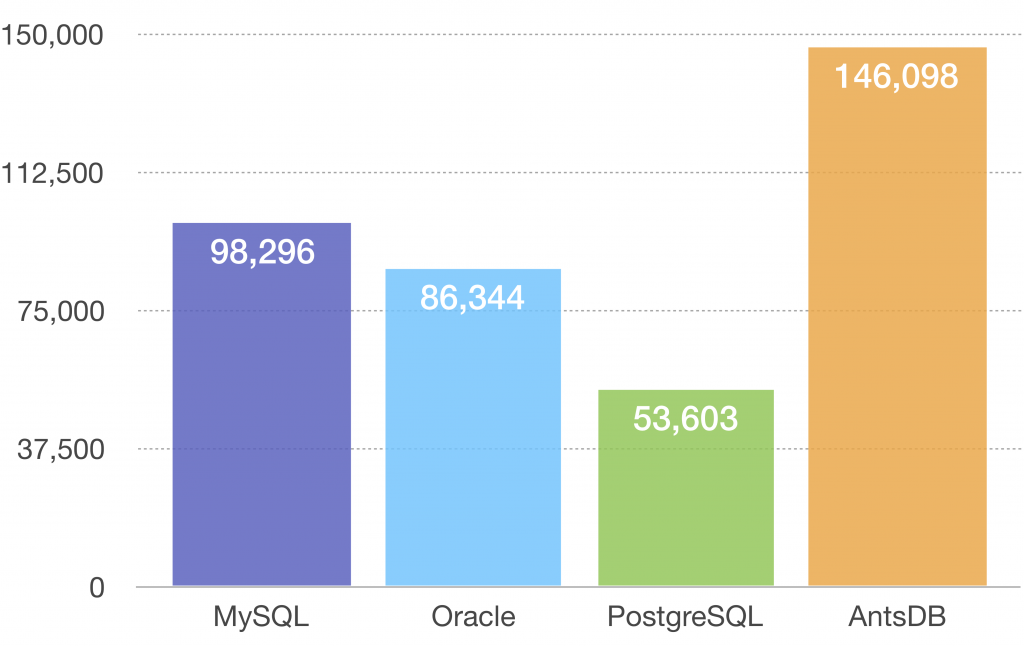
Read Heavy Test
The test was conducted using different number of threads. All tested databases achieved the highest throughput with 24 threads as show in the diagram below. Unit of measurement is transactions/second.
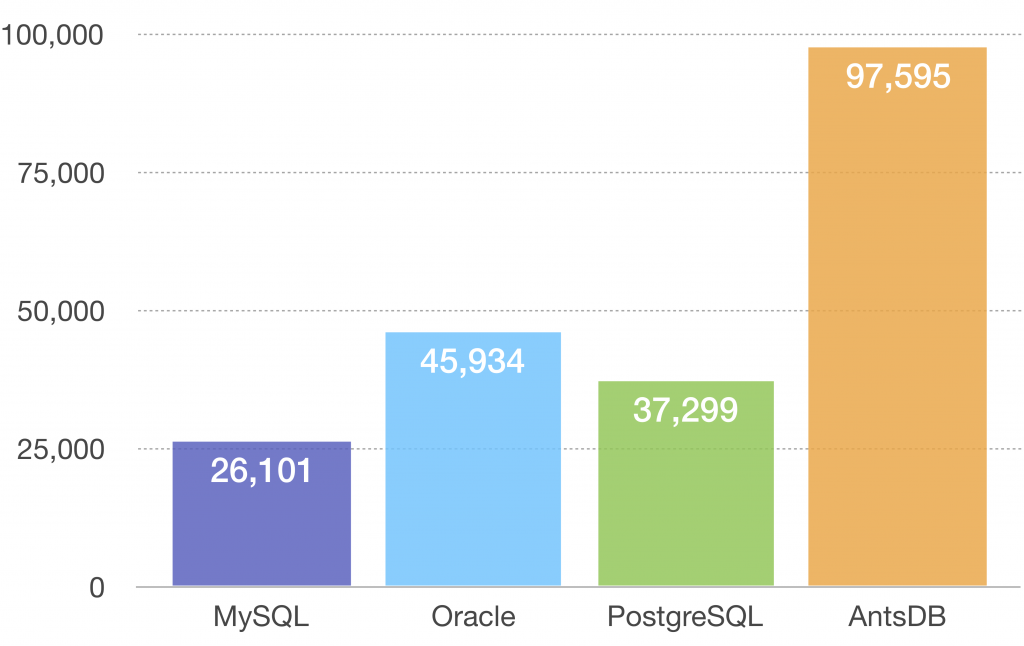
Write Heavy Test
The test was conducted using different number of threads. All tested databases achieved the highest throughput with 24 threads as show in the diagram below. Unit of measurement is transactions/second.
Conclusion
AntsDB has a clear lead over the other popular databases across all test categories. Internally, AntsDB has adopted a design vastly different from the traditional database engines. The locking is achieved using CPU level atomic operation. Files are organized using Log Structured Merge Tree. Index is implemented using lockless skip list. All disk I/O is done using memory mapped file. These techniques all together shows a significant advantage.
Due to the resource constraint, both the database server and test software ran on the same hardware so that part of the system resource were consumed by the benchmarking program. It is less perfect because in reality applications and database are likely to run on different machines. However we are expecting better performance with a dedicated database server.
AntsDB 18.04.04 release with replication support
Database replication is widely used in many organizations. It helps to bring real-time data feed to another place for safety, integration or analytic purpose. We are glad to announce that starting from 18.04.04 release, AntsDB supports real-time data replication.
With the replication support, changes occurred in AntsDB can be replicated to another slave AntsDB/MySQL database in real-time. The replication supports both DDLs and DMLs thus target database will never be out of sync with the active one. Instruction to configure it can be found in the manual .
The new release can be found in our download page.
AntsDB 17.12.04 has been released
AntsDB 17.12.04 has been released with improved compatibility, better stability and features critical to large organizations.
- Multiple instance support. Now more than one AntsDB instances can be installed in a single HBase cluster. It is achieved by mapping the system metadata namespace ANTSDB to a namespace specified by ‘humpback.hbase-conf’. For details, please refer to https://github.com/waterguo/antsdb/wiki/Configuration
- Native authentication support. In addition to Kerberos base authentication, AntsDB now let user manage user name and passwords inside AntsDB. For details, please refer to https://github.com/waterguo/antsdb/wiki/Security
- Backup and restore. AntsDB now supports the official backup utility from MySQL – mysqldump – to create database dump file. For details, please refer to https://github.com/waterguo/antsdb/wiki/Backup-and-Restore
- Semi HA. Unexpected accidents, ranging from software failures to hardware malfunctions, could happen. Now a new AntsDB installation can be set up to resume the interrupted workload in a few minutes when the worst situation occurs. For details, please refer to https://github.com/waterguo/antsdb/wiki/High-Availability.
Downloads are available from Download page.
HBase, Zeppelin and the Mighty Spark
Hadoop is all about computation power and scalability. When it comes usability it commonly known lacking. Apache Zeppelin is a young project from Apache community that focuses on data visualization. It is earning people’s love because it is filling the missing piece. Recently I came across a project in which I need to built an analytic solution using Zeppelin, HBase and Spark. They are all standard and popular software. “Should be easy task” was my first thought. It turned out to be a daunting task since HBase connector is not a built-in in Spark. In the rest of this article, I will go through the steps to make it work.
Choosing HBase Connector
Unlike the other Hadoop components such as HDFS, Hive etc, Spark has no built-in connector to access HBase data. There is a few choices available:
- HBase Spark is the official connector from HBase project. It is relatively a young project comparing to other choices and comes with little documentation.
- Spark on HBase is backed by Hortonworks and has a longer history than HBase Spark project
- Spark HBase Connector is another connector with very good documentation.
Actually, this is not a choice user needs to make. You should always go with the one comes with your Hadoop distribution. The Hadoop vendors such as Cloudera and Hortonworks built their only version of Hadoop, HDFS, Spark, HBase etc. Lots of times, things just don’t work on a specific distribution if you grab a random 3rd-party library.
My project is built on Cloudera 5.7. It comes with HBase Spark connector. I am glad it is the official connector from HBase community. But there is almost no documents. It is said good developers never write documents. I hope it is true in this case.
Configure Zeppelin
Spark is a built-in Zeppelin. In our case, the HBase Spark Connector comes with Cloudera only works with their own version of Spark. The first few changes is in zeppelin-env.sh file under the conf folder.
# spark folder from your distribution export SPARK_HOME=/usr/lib/spark # hbase folder from your distribution export HBASE_HOME=/usr/lib/hbase # if you want Zeppelin to execute your spark code in yarn. you should have the proper core-site.xml, hdfs-site.xml and yarn-site.xml in this folder HADOOP_CONF_DIR=~/hadoop-conf
Now go to Interpreter configuration located at the top right corner of Zeppelin UI. Add the following jar file to the Dependencies section of Spark interpreter. Noted file name and location varies depending what distribution you use.
/usr/lib/hbase/lib/hbase-client-1.2.0-cdh5.12.0.jar /usr/lib/hbase/lib/hbase-common-1.2.0-cdh5.12.0.jar /usr/lib/hbase/lib/hbase-spark-1.2.0-cdh5.12.0.jar /usr/lib/hbase/lib/hbase-server-1.2.0-cdh5.12.0.jar /usr/lib/hbase/lib/hbase-protocol-1.2.0-cdh5.12.0.jar /usr/lib/hbase/lib/hbase-hadoop-compat-1.2.0-cdh5.12.0.jar /usr/lib/hbase/lib/htrace-core-3.2.0-incubating.jar
Restart Zeppelin, now you should be able to use HBase Spark connector.
Exercising Spark
Now, let’s write some code to produce meaningful result. I have a database with the following tables and columns in HBase from a help desk application. I am trying to produce a chart showing the number of tickets assigned to different departments.
| Table | Column Family | Column | |
|---|---|---|---|
| tickets | d | ticket_id | primary key of the ticket table |
| tickets | d | subject | subject of the ticket |
| tickets | d | department_id | department id the ticket is assigned to |
| departments | d | department_id | primary key of the departments table |
| departments | d | name | name of the department |
Go to the Zeppelin Notebook, first import the APIs we will be using
%spark import org.apache.spark.SparkConf import org.apache.spark.SparkContext import org.apache.spark.sql.SQLContext import java.io.File import org.apache.hadoop.conf.Configuration import org.apache.hadoop.hbase._ import org.apache.hadoop.hbase.client._ import org.apache.hadoop.hbase.util._ import org.apache.hadoop.hbase.spark._ import org.apache.spark.sql.Row import org.apache.spark.sql.types._ import sqlContext.implicits._
Secondly, we need some helper functions that give us the HBase connection and convert HBase bytes to meaningful values
def getString(r:Result, c:String):String = {
var cell = r.getColumnLatestCell(Bytes.toBytes("d"), Bytes.toBytes(c))
Bytes.toString(CellUtil.cloneValue(cell))
}
def getInteger(r:Result, c:String):Integer = {
var cell = r.getColumnLatestCell(Bytes.toBytes("d"), Bytes.toBytes(c))
Bytes.toInt(CellUtil.cloneValue(cell))
}
def getHbaseConfig():Configuration = {
val conf = HBaseConfiguration.create()
conf.set("hbase.zookeeper.quorum", "quickstart.cloudera")
return conf
}
def getHbaseContext():HBaseContext = {
val conf = getHbaseConfig()
new HBaseContext(sc, conf)
}
Next is the most interesting part. The following code will build the mappings between Spark tables and HBase tables
val hc = getHbaseContext()
var rdd = hc.hbaseRDD(TableName.valueOf("test", "tickets"), new Scan())
case class Ticket(tick_id:Integer, department_id:Integer, subject:String)
var map = rdd.map( x => {
val subject = getString(x._2, "subject")
var ticket_id = getInteger(x._2, "ticket_id")
var depart_id = getInteger(x._2, "department_id")
Ticket(ticket_id,depart_id,subject)
})
map.toDF().registerTempTable("tickets")
val rddDepartments = hc.hbaseRDD(TableName.valueOf("test", "departments"), new Scan())
case class Department(department_id:Integer, name:String)
val mapDepartment = rddDepartments.map( x => {
val id = getInteger(x._2, "department_id")
val name = getString(x._2, "name")
Department(id, name)
})
mapDepartment.toDF().registerTempTable("departments")
I choose to use Spark Datarframe in this example because it can be used with Spark SQL later. It is an option of course. Without Dataframe, you can process data using RDD API. It is more complex but can do things that SQL can’t.
Execute the above code, we now have tables tickets and departments registered in the Spark Context
Charts with Spark SQL
Open a new paragraph in Zeppelin notebook. Write the following code. It will give the top 5 departments with the highest ticket count.
%spark.sql select d.name, count(*) count from tickets t join departments d on (t.department_id = d.department_id) group by d.name order by count(*) desc limit 5

Switch over to pie chart, it will show a pretty chart as below

Version of the Software
For your reference, below are the versions of the software used in the setup.
| Cloudera CDH 5.12.0 |
| Zeppelin 0.7.3 netinst |
Conclusion
Despite the painful configuration that makes the whole setup to work. Zeppelin and Spark is a sweet couple that is both productive and powerful. It saves significant amount of work to write code, debug logic and visualize the data. With the power of Hadoop/Spark, the same logic can be distributed to thousands of machines and process billions of records.
AntsDB Architecture
AntsDB takes a different approach than most mainstream relational databases. The market dominators, aka the old school RDBMS, follows very similar architecture despite small differences in features and performance. If you open the hood, you will see b-tree, redo/undo log, thread pool, transaction manager, metadata manager, lock manager etc. Very much like the gasoline vehicles, it is always the same components but in different shapes, sizes and performance characteristics depending on what brand/model of the car you are looking at.
The trending NoSQL/NewSQL databases are very different than the old school RDBMS. But among them, they also share very similar architecture. Pretty much all of them are built with write ahead log, log structured merge tree, cluster management, replication etc.
AntsDB doesn’t really fall into any of the two categories above. Our mission is to create a hybrid database engine that is both OLTP and OLAP. AntsDB is OLTP because it provides features that is critical in building a front-end application such as ACID, sub-millisecond latency, rich transaction management, SQL compliance and powerful lock management. It is also a OLAP because the storage AntsDB sits on is a data warehouse. AntsDB also acts like a middleware. It is a stateless transaction processor with a big local cache.
Thus it leads to an architecture shown in the diagram below.
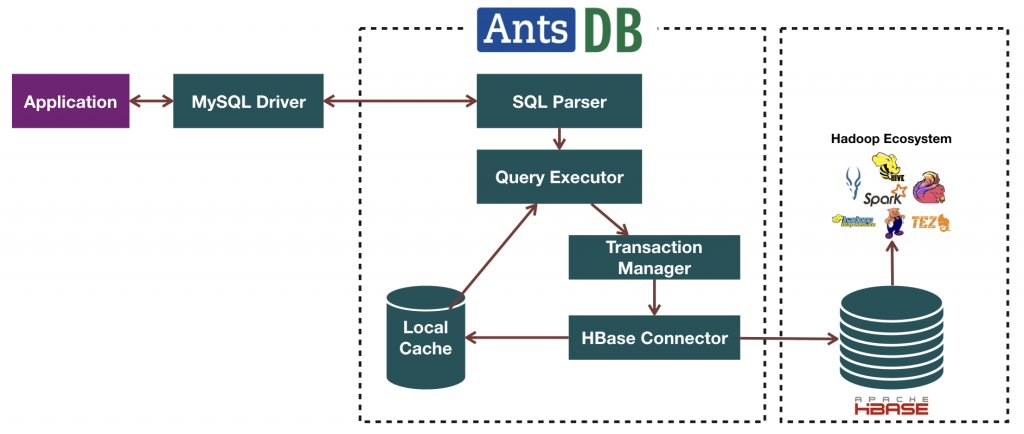
AntsDB Architecture
AntsDB is built with 3 layers. The outmost layer is the MySQL compatibility layer. There are two components: network protocol and SQL parser.
The network protocol is a full MySQL 5.5 protocol implementation. It is written using asynchronous I/O with the help from popular Netty project. Asynchronous I/O grants AntsDB the advantage to serve large amount of current users with a very small thread pool. Traditional DBMS uses synchronous I/O. It has to create exclusive thread for each user. Thread is an expensive system resource. It doesn’t scale well.
SQL is a high level language. We need to break the complex logic into smaller and simpler parts such as functions, operators, joins etc. The parser is responsible of this task. At the end of parsing, it generates a number of “instructions” which runs in the virtual database machine. Result of the parser is cached in a small pool in memory. If the frond-end application sends duplicate SQL statements, the expensive parsing phase can be simply skipped. Most applications today do that with prepared statements.
We wanted AntsDB to be not only compatible with MySQL but also other types of database in the future. Thus it comes with the idea of database virtualization. VDM – virtual database machine – is what makes it come true inside AntsDB. VDM is a runtime environment with hundreds of small logic unit such as functions, joins, operators etc. Beside the small building blocks, there are 3 important components in VDM serving them.
Transaction Manager makes sure that multiple data manipulations act as a single unit of work. It uses a 64 bit number internally to track every single transaction in the system. Once the transaction is completed. It assigns another 64 bit number to the updates as the version of the update. The version is subsequently used in transaction isolation and MVCC (multi-version concurrency control).
Metadata Manager manages the life cycle of user objects, aka as tables, columns, constraints etc. It maps human readable names to memory locations, file locations and unique identifiers that works efficiently at the hardware level.
SQL query is a high level abstract language. Typically database software needs to break the query into many joins, table lookups and table scans. Unfortunately, there are many different ways to do it. Some could be more efficient than the others. That’s where the query planner kicks in. It evaluates all possibilities intelligently and decides the least expensive way of execution.
At the very bottom of the layers sit the AntsDB KV – key value store. We have the top layer responsible of MySQL compatibility, mid layer manages the complexity of SQL language. The AntsDB KV’s job is to deal with performance and concurrency.
At the heart of AntsDB KV, it is the LSMT store. LSMT – log structured merge tree – is a way to organize database files. It’s been known to be much superior in terms of I/O efficiency than page based storage used in most mainstream databases. The data in LSMT is more compact. It takes advantage of high throughput sequential I/O while page store is depending on slow random I/O. Inside LSMT, AntsDB uses skip list data structure other than B tree used in most mainstream databases. Skip list utilizes CPU level atomic operations to mange data contention and performs extremely well in high current situations while B tree uses expensive mutex.
As a database, AntsDB has to be prepared for the worst. Power can go down. Hardware can malfunction. We use a technique – write ahead log, aka redo log – exists in almost all databases today to recover from failures. As soon as the transaction commits, updates is guaranteed to be written to the WAL. After a system crash, AntsDB uses data from WAL to rebuild LSMT next time it starts.
The last component in KV store is the replicator. Its responsibility is to send data to HBase as soon as the updates is committed in a sub-second manner.
Above summarizes the AntsDB architecture from a very high level. We will cover some of the components in more detail later.
AntsDB beta2 has been released
There are significant performance and stability improvements in this release. The most important of all, the cache implementation has been completely overhauled. It includes a new resilient file format which resists both software and hardware failures. The data is safe and sound as long as the machine can reboot. The cache algorithm uses lock-free skip list under the hood. Our benchmark shows the new cache implementation is able to power half million write operations or more than 1 million read operations per second on commodity hardware.
Data replication algorithm from AntsDB to HBase has been improved. It will package multiple row updates or deletes from the same table in one API call, saving lots of network roundtrips. The new replicator is able to handle tens of thousands of operations per second. But the real performance is largely depending on HBase.
In this release, AntsDB starts to support full text search. It is critical for content management applications such as MediaWiki, the software powers Wikipedia. Underneath, AntsDB full text search uses popular Lucene library.
You are welcome to try our beta2 release. The download link can be found at Download page.